Deep Contextualized Word Representations
Introduction
Deep Contextualized Word Representations has been one of the major breakthroughs in NLP in 2018. Able to easily replace any word embeddings, it improved the state of the art on six different NLP problems.
(Note: I use embeddings and representations interchangeably throughout this article)
High quality representation of words has to take into account both the syntax and how it varies in use across linguistic contexts.
“Alice gave her favourite book to Bob”
“He was told to book a hotel room for their upcoming trip”
Both of these sentences use the word book but the meaning of the word is completely different in each of the cases. This is known as polysemy - the capacity for a word to have different meanings based on its context. Current word representations use a single vector for each word, regardless of context. However, a vector representing a word should depend on the words surrounding it. If it doesn’t, there will always be a limit on the usefulness of the representation.

This is where Embeddings from Language Models (ELMo) comes in. Despite sharing its name with the furry red muppet from Sesame Street, it is an innovative embedding technique that helps to improve the usefulness of word embeddings.
ELMo: Embedding Language Models
Widely used methods such as GloVe make use of context words to generate word embeddings. ELMo takes the entire input sentence as a function, passing through a 2 layer biLM to train a language model on the dataset, and using the hidden states of the LSTM for each token to compute a vector representation of each word.
Bidirectional Language Models (biLM)
A language model predicts the probability of a given sequence. Given two sequences:
Humpty Dumpty sat on the wall
Humpty Dumpty sat on the ceiling
the language model assigns a higher probability to the first sentence.
The probability of a sequence of words is equal to the product of the probabilities of each word given the previous words in the sequence. Symbolically, this is expressed as
A bidirectional language model also has a backward pass, but the authors simply reversed the input sequence to pass in the words in reverse order. Therefore they would pass in:
wall the on sat Dumpty
and the language model would be expected to predict ‘Humpty’. This is expressed as,
In their implementation, they do share some weights for the forward and backward LM, but do not provide more specifics. The loss function maximises the log likelihood of both the forward and backward directions.
ELMo
For each token , a -layer biLM computes a set of representations (forward and backward LM for each layer and the initial token layer).
is the token layer and is the forward and backward LM for each layer.
Since each representation of a word is a function of the entire sequence, this allows a word to have different representations based on its neighbours - solving the polysemy problem from earlier. This representation is completely task agnostic at this point.
ELMo refers to a task specific combination of the intermediate layer representations in the biLM. Softmax-normalized weights and a scalar parameter are learned for each task. learns the mapping from the biLM to a task specific vector while is for practical purposes of scaling the vector - this helps during the optimization process.
Using biLMs for supervised NLP tasks
Most NLP tasks use embedded representations of words as input, which means that ELMo can be concatenated together with existing embeddings. The nice thing about ELMo is that the representation can be dropped in without changing the rest of the model, which means that you are usually going to get an improvement in performance for free!
The weights in the biLM layers and frozen and the ELMo vector is concatenated with and pass the combined representation into the task RNN. For some NLP tasks, improvements have been noted by including ELMo at the output of the task RNN, replacing output with . A set of output specific linear weights have to be learned in this case to take the ELMo in the output into account.
Pre-trained biLM architecture
The model uses a 2 layer biLSTM model with 4096 units and 512 dimension projections. The first layer also had a residual connection to the second layer.
Since language models need context independent embeddings to train, ELMos cannot be used as a embedding. Therefore a character based, word embedding was used with a 2048 character n-gram convolutional layer, followed by 2 highway layers and a linear projection down to a 512 embedding. Highway layers are more general versions of residual connections. Instead of adding the output from the lower layer and input of the upper layer together directly, each of them are assigned a weight which can be learned by the network.
Once pretrained, the biLM can compute representations for any task. In some cases, fine tuning the biLM on domain specific data results in improved downstream task performance. This is a type of domain transfer - use a model trained on a general domain and tweaking it slightly to fit it for a specific domain.
Evaluation
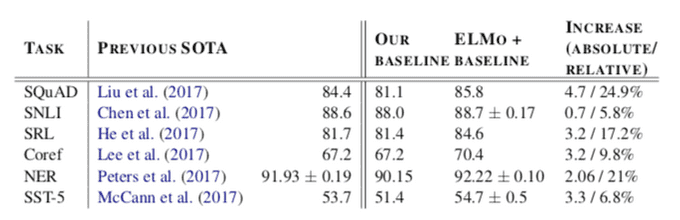
ELMo was evaluated on a wide range of six NLP tasks. Impressively, simply adding ELMo establishes a new state-of-the-art result. It reduces error rates from 6 - 20% over previous strong base models. Refer to the paper for more information about the task, datasets and experiments.
Analysis
The analysis section of this paper was a part I found really interesting. Here is some of the things that the authors discovered through their experiments.
- While previous contextual representations only used the last layer, using all the layers improves performance across the board over different tasks. Using just the last layer from ELMo is still better than baseline.
- Including ELMo for both input and output improves performance for the SNLI(Textual Entailment) and SQuAD (Question Answering) datasets. A possible explanation is that both of the architectures use attention layers after the biRNN, so introducing ELMo could allow the model to attend directly to the biLM’s internal representations.
-
The biLM representations captures words with different meanings based on context. This is demonstrated with a nearest neighbours on the word ‘play’ done on GloVe vs biLM. GloVe returns many sports related verb and nouns, but the biLM is able to offer different meanings based on the sentence that ‘play’ appears in.
- The biLM is also tested on word sense disambiguation and Part Of Speech (POS) tagging to examine if it is able to disambiguate and capture basic syntax.
- Adding ELMo to a model allows the model to converge quicker, and achieve better performances on smaller datasets.
- By visualizing the magnitude of softmax-normalized learned layer weights, it is seen that at the input layer, the task model favours the first layer. At the output layer, the task model leans slightly towards the lower layers.
AllenNLP
The authors of the paper are also the maintainers of AllenNLP, an excellent open source library for NLP research. They also made an awesome set of slides talking about best practices for NLP research. Check it out if you have not!